

Introduction
Often times you need dummy data or fake data to test the software you are working on. The real pain is to get the proper data for testing. If you are lucky Google search may yield you some datasets but sometimes it may be a futile exercise.
What if we can generate the dummy data quickly and load it into Pandas dataframe so that you don’t have to spend time searching for the right dataset? Yes, it’s possible with the help of the Python Faker package. In this article, you are going to learn how to use Faker to generate fake/dummy data.
Faker
As mentioned in the official documentation, this Python Faker library is inspired by PHP Faker, Perl Faker, and Ruby Faker.
Installation
The below command will install the Faker library without any hassle. However, note that starting from version 4.0.0, Faker only supports Python 3.6 and above. If you are still using Python 2.x then you should use Faker 3.0.1.
pip install Faker
Usage
You need to first create a Faker object and then run the methods on the faker object to get the required fake data. In the below example, we have created a faker object called fake and then ran the name, address, etc. method on the object to get the required data.
>>> import faker
>>> fake = faker()
>>> fake.name()
'Lucy Cechtelar'
>>> fake.address()
'0535 Lisa Flats\nSouth Michele, MI 38477'
If you are curious to know all the available methods, you can run the below command.
>>> dir(fake)
Localization
By default, the Faker generates the data in English and US-centric details like name, address, etc, i.e by default 'locale=en-US’ considered.
What if you want localized data? This can be done by passing the locale parameter while creating the faker object. For example: 'hi_IN' for Hindi (India), 'jp_JP’ for the Japanese (Japan), 'it-IT' for the Italian, etc. to get the name, address, etc, in the respective language. Refer to the example below.
The list of all the supported languages and countries is found at this link.
# Generating fake data in Hindi
>>> fake = Faker(locale='hi_IN')
>>> for _ in range(2):
... print(fake.name())
मोहिनी काले
फ़ातिमा ड़ाल
# Generate fake data in Japanese
>>> fake = Faker(locale='jp_JP')
>>> for _ in range(2):
... print(fake.name())
山口 くみ子
斎藤 桃子
# Generate fake data in Italian
>>> fake = Faker(locale='it_IT')
>>> for _ in range(2):
... print(fake.name())
Sig.ra Serafina Magrassi
Martino Tartaglia
Providers
The providers are nothing but the common properties that are grouped together. For example, faker.providers.credit_card provides details credit card information, faker.providers.address provides details about address details such as city, zip, state, country, etc, and faker.providers.geo provides detail about latitude, longitude, country code, time zone, etc. Hope you get an idea.
There are two different types of provides — standard providers and community providers that are described below.
Standard Providers — There are currently 23 standard providers as listed below.

Community Providers — There are some community-added providers as listed below which you can use based on your requirement. For example, if you wanted to fake data for Airtravel or Credit Score or Vehicle, etc. you can use the below-listed providers. You can also create your own providers and add them to the list of community providers.

Note: Not all the providers are available for all the countries. For example, for India, an automative provider is not available. In such a case, Faker defaults to en_US values. It means that even if you code fake = Faker(locale='hi_IN'), en_US fake values are generated by the Faker. The same logic applies to geo provider as it is available only for six countries as of this writing, and so on.
Unique Values
Sometimes you want to make sure that unique names or addresses, etc are generated so there are no duplicate values. You need to use fake.unique.<method> method as shown below. You can replace <method> with any faker methods. The below is an example of getting unique names.
>>> fake = Faker(locale='en_US')
>>> for _ in range(5):
... print(fake.unique.name())
Jesus Todd
Kevin Snyder
Daniel Dixon
Michael Thomas
Jessica Miller
Reproducible Data
Faker also provides an option for reproducible data. In Machine learning parlance, we use the term called the seed. The same concept of seed is used here for reproducible data.
In the below example, we have added seed value 42. So, every time you run the below code, it always generates the same name Allison Hill so reproducibility is maintained.
>>> fake = Faker(locale='en_US')
>>> Faker.seed(42)
>>> print(fake.name())
Allison Hill
Examples
Now that you have understood how Faker can be used let’s apply the knowledge we gained so far on some examples.
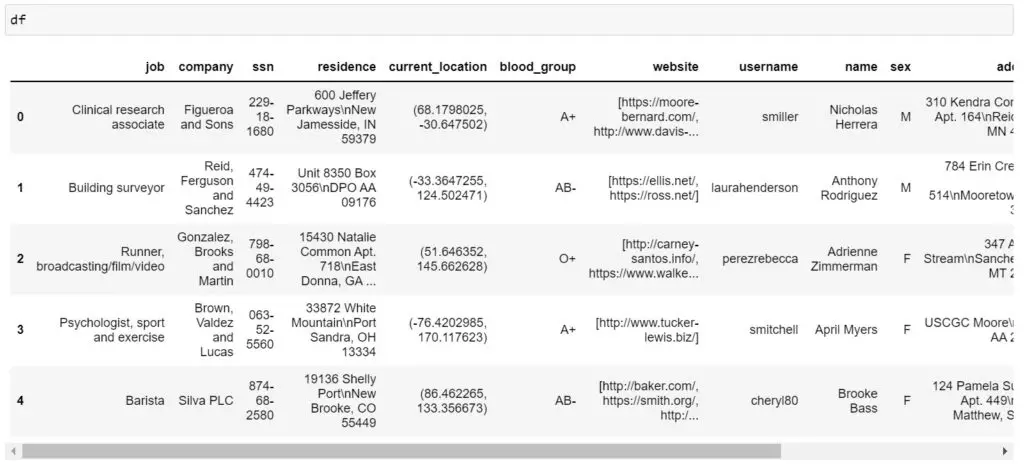
(1) Generate 10 fake profiles
Faker provides a built-in method called profile that can be used to generate the profiles containing details such as job, company, SSN, name, address, etc.
import pandas as pd
from faker import Faker
Faker.seed(42)
fake = Faker(locale='en_US')
fake_workers = [fake.profile() for x in range(5)]
df = pd.DataFrame(fake_workers)
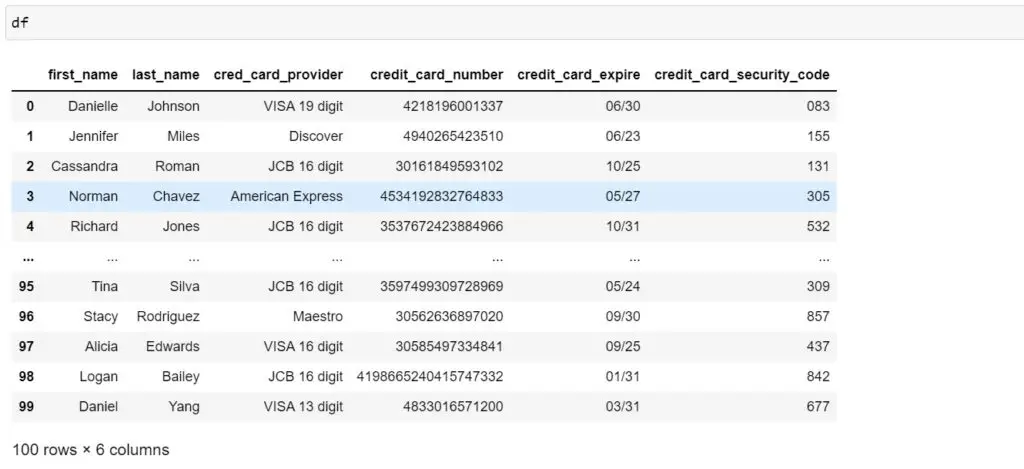
(2) Generate 100 fake credit card details
You can use the credit card methods available on the faker to generate credit card details. Along with credit card methods, we have also added first_name and last_name. However, you can add as many details as you want that are relevant for you.
import pandas as pd
from faker import Faker
Faker.seed(42)
fake = Faker(locale='en_US')
fake_credit_cards = [
{'first_name': fake.first_name(),
'last_name': fake.last_name(),
'cred_card_provider': fake.credit_card_provider(),
'credit_card_number': fake.credit_card_number(),
'credit_card_expire': fake.credit_card_expire(),
'credit_card_security_code': fake.credit_card_security_code()}
for x in range(100)]
df = pd.DataFrame(fake_credit_cards)
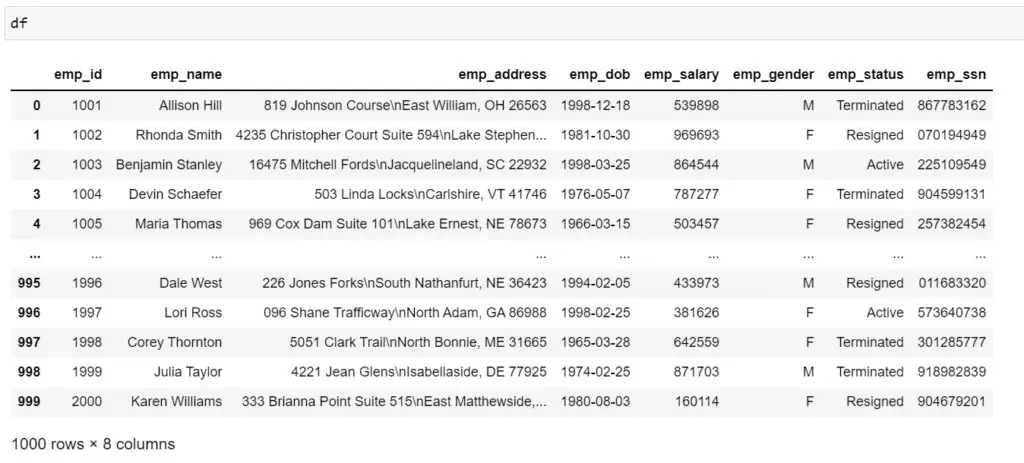
(3) Generate 1000 employee details
The data contains details such as employee id, name, address, dob, salary, gender, etc.
For this example, we will make use of the default locale i.e. ‘en_US’. As you can see we are making use secrets module to generate SSN. You could also make use of the random module for some of the features.
import secrets
import string
import pandas as pd
from faker import Faker
Faker.seed(42)
fake = Faker(locale='en_US')
fake_workers = [
{'emp_id': '',
'emp_name': fake.name(),
'emp_address': fake.address(),
'emp_dob': fake.date_between(start_date='-60y', end_date='-20y'),
'emp_salary': fake.random_number(digits=6, fix_len=5),
'emp_gender': fake.random_element(elements=['M', 'F']),
'emp_status': fake.random_element(elements=['Active', 'Terminated', 'Resigned']),
'emp_ssn': ''.join(secrets.choice(string.digits) for i in range(9))
}
for x in range(1000)]
df = pd.DataFrame(fake_workers)
df['emp_id'] = range(1001,2001)
Conclusion
I hope these three examples gave you some idea on how to use Faker to generate the fake/dummy data. We only used some of the methods, but Faker offers many functions related to date time, random numbers/digits, internet, etc. Be sure to check the output of dir(fake) to see all the available methods for generating the fake data.
