

Introduction
Text Classification is one of the most popular and widely used use-cases of Machine Learning and NLP (Natural Language Processing). It can be used to classify spam vs non-spam emails, classify business documents into different categories, and sentiment analysis of Tweets, etc.
In this practical guide, you’ll understand how to use Bag of Words and TF-IDF for text classification with TensorFlow. The advanced text feature extraction methods such Word2Vec, GloVe, fastText, etc. will be covered in future articles.
We’ll be using the IMDb Dataset of 50,000 movie reviews from Kaggle. You can download the dataset from here. Otherwise, you can create a new notebook in Kaggle and follow along.
Quick Recap
Before we delve into coding, let’s take a quick recap of how text features are extracted in Bag of Words and TF-IDF methods –
Bag of words (CountVectorizer): Each word in the collection of text documents is represented with its count in the matrix form. Refer below –

TF-IDF: Each word from the collection of text documents is represented in the matrix form with TF-IDF (Term Frequency Inverse Document Frequency) values. Refer below —

You probably would have used it with Scikit-learn. In this blog, you’ll implement both methods directly in TensorFlow. Let’s get started by importing all the libraries.
Import libraries
Imports all the required libraries and modules.
import os
import numpy as np
import pandas as pd
pd.options.plotting.backend = "plotly"
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import losses
from tensorflow.keras.utils import plot_model
from tensorflow.keras import Sequential
print("Tensorflow version:", tf.__version__)
from sklearn.model_selection import train_test_split
Import dataset and EDA
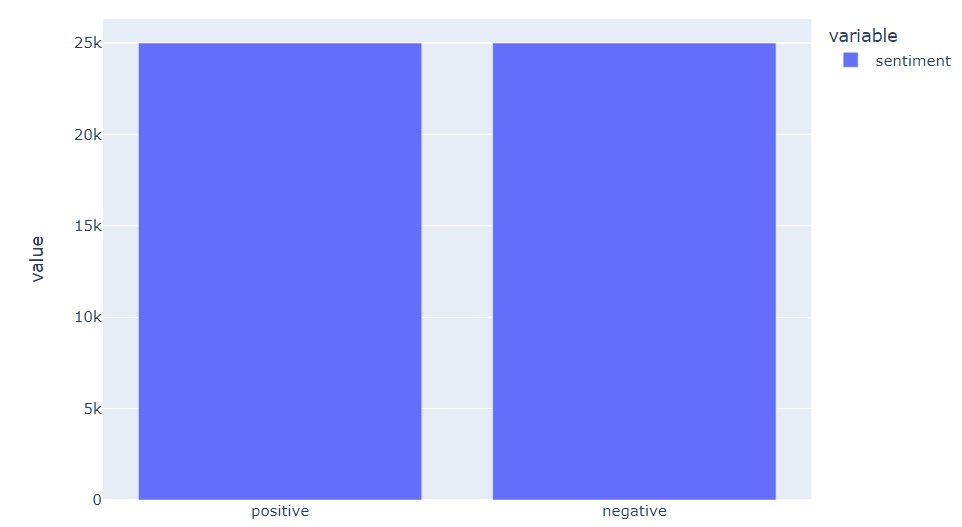
The dataset for this article comes from Kaggle. The dataset contains 50,000 reviews. The positive and negative comments are equally distributed (balanced classes). Since we are working with a balanced dataset, we don’t have to worry about class imbalance issues.
df = pd.read_csv('/kaggle/input/imdb-dataset-of-50k-movie-reviews/IMDB Dataset.csv')
df['sentiment'].value_counts().plot(kind='bar')
A quick look at the first 2 reviews and its sentiment —

df['sentiment'] = df['sentiment'].map({'positive': 1, 'negative': 0})
Data cleaning is an important step in the NLP pipeline. Though we are skipping this step here to keep this article short, we strongly suggest you apply the necessary data-cleaning techniques such as punctuation removal, stop-word removal, lemmatization, etc.
However, note that the TextVectorization method we are using for text feature extraction in the next section applies the default text cleaning and can optionally accept a custom function for data cleaning.
Train test split
The next step is to split the data into train and validation sets..For the given dataset we only have one file IMDB Dataset.csv. So, let’s split the dataset into the train, validation, and test set.
train, test = train_test_split(df, test_size=0.2, stratify=df['sentiment'])
train, validation = train_test_split(train, test_size=0.2, stratify=train['sentiment'])
train.shape, validation.shape, test.shape
Next, create TensorFlow dataset objects for training and validation dataset using the method from_tensor_slices() as shown below.
training_dataset = tf.data.Dataset.from_tensor_slices(
(train['review'].values, train['sentiment'].values)).batch(batch_size=32)
validation_dataset = tf.data.Dataset.from_tensor_slices(
(validation['review'].values, validation['sentiment'].values)).batch(batch_size=32)
Text feature extraction
As mentioned earlier, CountVectorizer and TF-IDF are the commonly used text feature extraction methods. We can achieve this directly on the pandas dataframe using Scikit-learn’s CountVectorizer and TfidfVectorizer.
But, we’ll use TensorFlow provided TextVectorization method to implement Bag of Words and TF-IDF. By setting the parameter output_mode to count and tf-idf and we get Bag of Words and TF-IDF outputs respectively. Note that the output_mode also takes two more parameters — int and multi-hot that we are not covering in this article.
The advantage of using the TextVectorization method is that you can add this vectorization as another layer when building the model which you’ll see in the next section.
The syntax for TextVectorization –
tf.keras.layers.TextVectorization(
max_tokens=None,
standardize='lower_and_strip_punctuation',
split='whitespace',
ngrams=None,
output_mode='int',
output_sequence_length=None,
pad_to_max_tokens=False,
vocabulary=None,
idf_weights=None,
sparse=False,
ragged=False,
encoding='utf-8',
**kwargs
)
- max_tokens — the maximum length of the vocabulary. This must be used if
pad_to_max_tokensis set toTruemeaning if the size of the string is less than max_tokens the remaining characters are padded with zero. - standardize — denotes how to clean the text. The default value is
lower_and_strip_punctuationi.e. text is converted to lower case and then all punctuations will be removed. The other options are —lower,strip_punctuationandNone. You can also write a custom standardization function and pass the function name to this. - split — used to control how to split the text. The values are —
None,whitespaceandcharacter. The default is whitespace. - ngram — ngram range. The possible values are —
None,integeror(integer, integer). If an integer is passed all ngrams up to that integer are considered. If the tuple of integers is passed then only ngram in that range is considered. - output_mode — controls the output. The possible values are —
int,multi-hot,count,tf-idf. - output_sequence_length — Used only if output_mode is set to int. This means that the output will be either padded or truncated so as to have the length as specified output_sequence_length.
- pad_to_max_tokens — Used only if output_mode is
multi_hot,count, andtf_idf.
Bag of Words (Count Vectorizer): To use the Bag of Words method, we need to set output_mode to count. The below code gives Bag of Words output and the maximum vocabulary size is set to 10000.
vocab_size = 10000
count_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=vocab_size,
output_mode='count'
)
count_vectorizer.adapt(train['review'].values)
TF-IDF: To use the TF-IDF text extraction method set output_mode to tf-idf. The below code gives TF-IDF output and the maximum vocabulary size is set to 10000. Also, we are using the ngram range (2, 3).
vocab_size = 10000
tfidf_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=vocab_size,
output_mode='tf-idf',
ngrams=(2, 3)
)
tfidf_vectorizer.adapt(train['review'].values)
After creating the TextVectorization objects, you should run the adapt method on the train set. This is similar to the fit method in Scikit-learn. The adapt method learns the vocabulary and stores it in the object. You can view the learned vocabulary using the get_vocabulary() method.

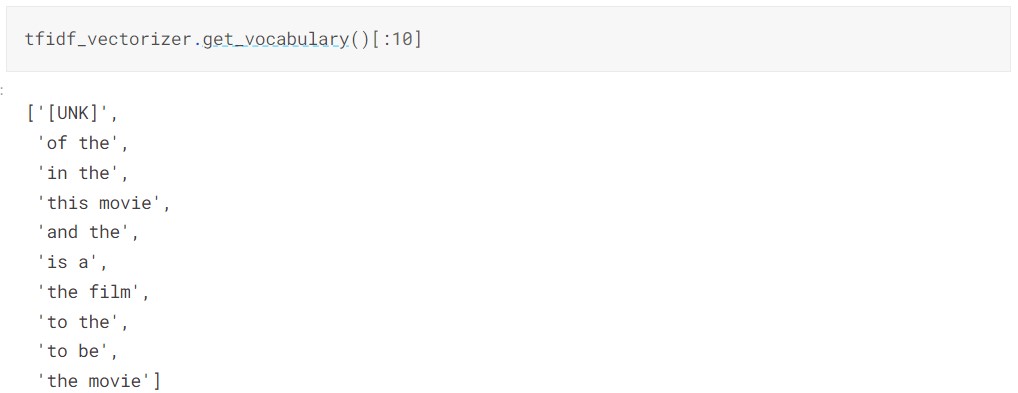
By providing the sample text to TextVectorizer objects you can see the output Bag of Words or TF-IDF, etc. The same thing happens when you are trying to predict the sentiment of the text. Notice in the next section that the vectorizer is added as the first layer in the model so that input text is vectorized first and then feed into dense layers and finally the prediction layer.

Model
Now we have everything ready to build the neural network model. In this section, we will build a separate model for each Bag of Words and TF-IDF, compile it, and finally train the model. Notice that the only difference between the models is the first layer i.e count_vectorizer in Bag of Words and tfidf_vectorizer in the TF-IDF model.
Bag of Words model
model = Sequential([
count_vectorizer,
layers.Dense(64, activation='relu', kernel_regularizer=L2(1e-3)),
layers.Dropout(0.1),
layers.Dense(64, activation='relu', kernel_regularizer=L2(1e-3)),
layers.Dropout(0.1),
layers.Dense(1, activation='sigmoid')
])
model.compile(
loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy']
)
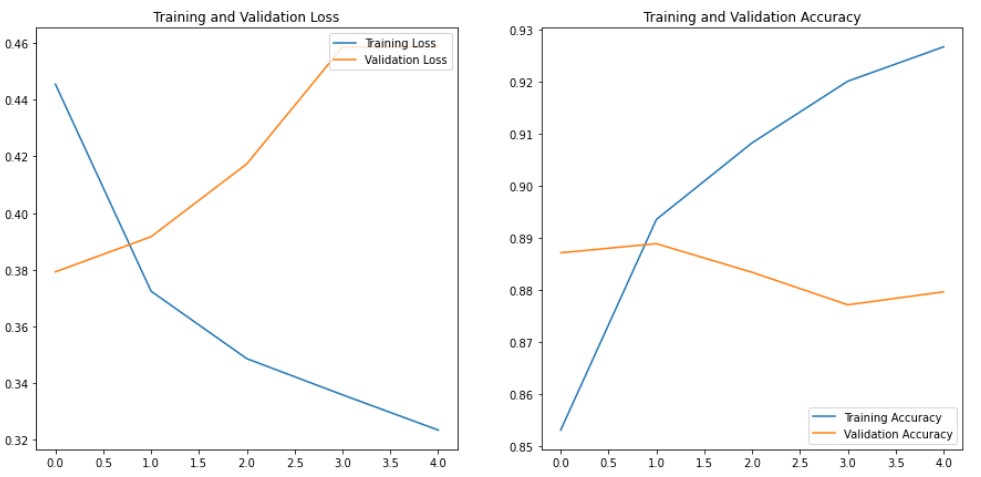
history = model.fit(
training_dataset,
steps_per_epoch=len(training_dataset),
epochs=5,
validation_data=validation_dataset,
validation_steps=len(validation_dataset)
)
TF-IDF model
model = Sequential([
tfidf_vectorizer,
layers.Dense(64, activation='relu', kernel_regularizer=L2(1e-3)),
layers.Dropout(0.1),
layers.Dense(64, activation='relu', kernel_regularizer=L2(1e-3)),
layers.Dropout(0.1),
layers.Dense(1, activation='sigmoid')
])
model.compile(
loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy']
)
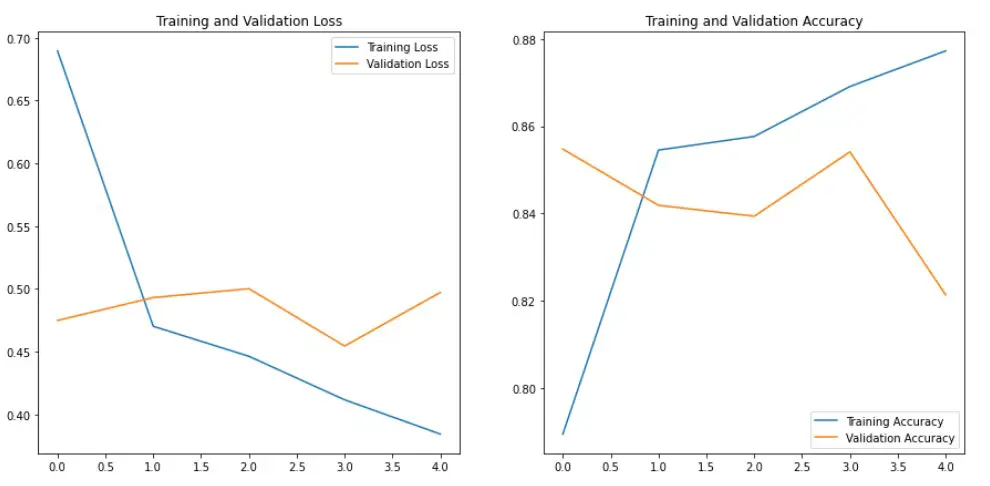
history = model.fit(
training_dataset,
steps_per_epoch=len(training_dataset),
epochs=5,
validation_data=validation_dataset,
validation_steps=len(validation_dataset)
)
Prediction
We have tried 2 different models based on Bag of Words and TF-IDF. The Bag of Words model gave us the best accuracy. Let’s get predictions on unseen or test data using the Bag of Words model. Since we have true labels for test data, find out the score for test data as well.
predictions = model_1.predict(test['review']).round()
accuracy_score(test['sentiment'].values, predictions)
In this article, we have built a simple sentiment analysis using Bag of Words and TF-IDF methods with TensorFlow. We achieved a decent accuracy score of ~86% accuracy on validation and test data from the Bag of Words model. You can further improve the model with different techniques — tuning TextVectorizer parameters (vocab size, etc.), regularization, dropout %, tuning hyperparameters of the model using KerasTuner, etc.
References
- https://www.tensorflow.org/tutorials
- https://www.tensorflow.org/api_docs/python/tf/keras/layers/TextVectorization
