

Introduction
If you are reading this article it’s obvious that you are interested in text summarization. At the same time, you also want to go a step further and build a text summarization app. But you don’t know how to do it as you don’t have front-end experience. Say hello to Streamlit. With Streamlit, you can build beautiful apps in hours without the knowledge of front-end technologies.
Trust me when I say you can actually build beautiful apps in 30 mins using Streamlit as the title of this article say. It only takes 10–15 minutes to figure out the features you need in your web app by referring to the official documentation. In the next 15–20 minutes, you can put together Streamlit and summarization python code, and your web is ready in under 30 minutes. Congratulations !! You just created your first ML web app using Streamlit.
In this article, we will be using BART and T5 transformer models for summarization.
Streamlit
Streamlit is an open-source app framework mainly used in Machine Learning and Data Science community. You can create simple yet effective web apps for your machine learning projects in hours with minimal effort and without front-end experience.
Installation
It’s always good practice to create a separate virtual environment. If you are using Windows, I suggest you use Anaconda navigator for creating a virtual environment and also to run the Streamlit application. As of this writing (9-Jan-2021), Streamlit is supported for Python 3.6 — Python 3.8.
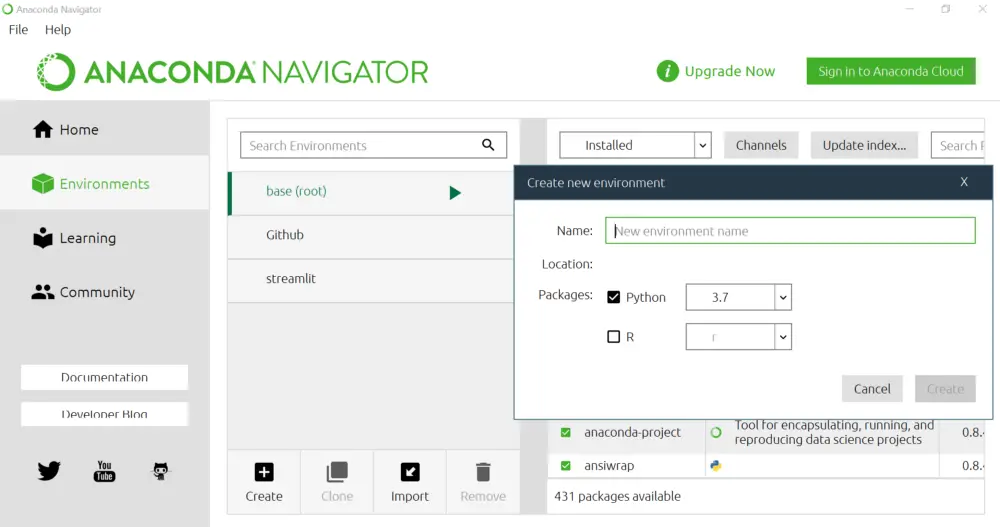
Once you create a virtual environment, open the terminal using the below option, and install all the required packages including Streamlit.
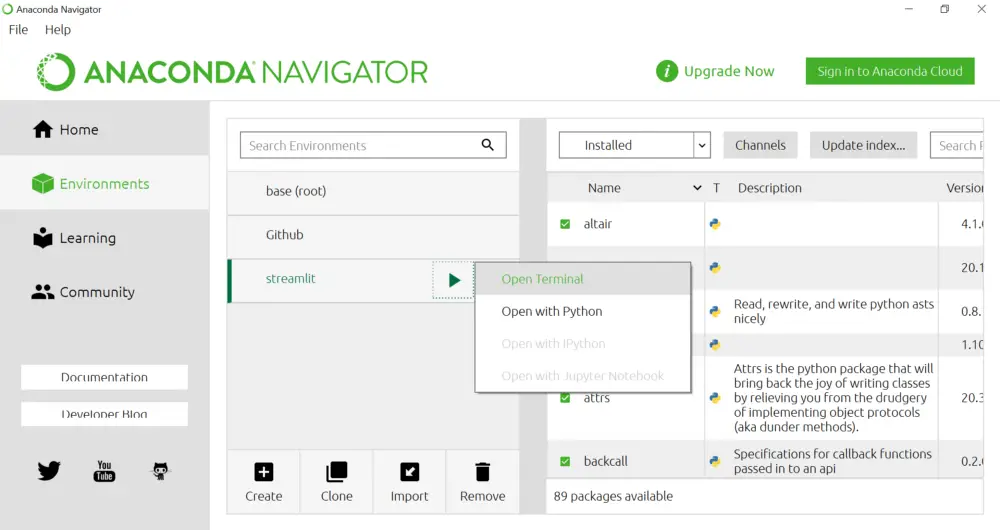
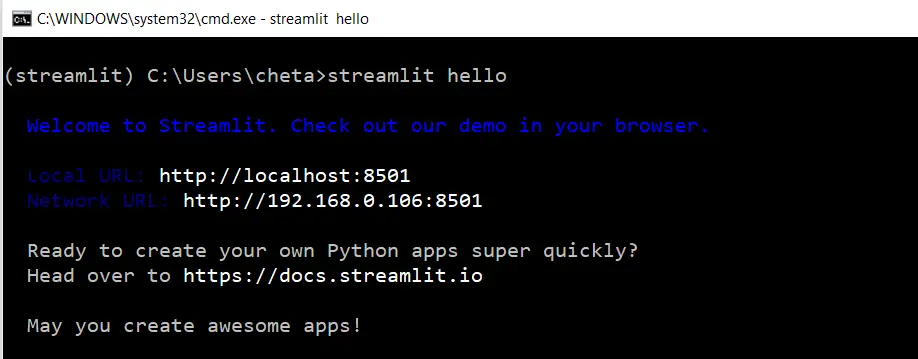
After the installation, run the below command to check if the installation is successful.
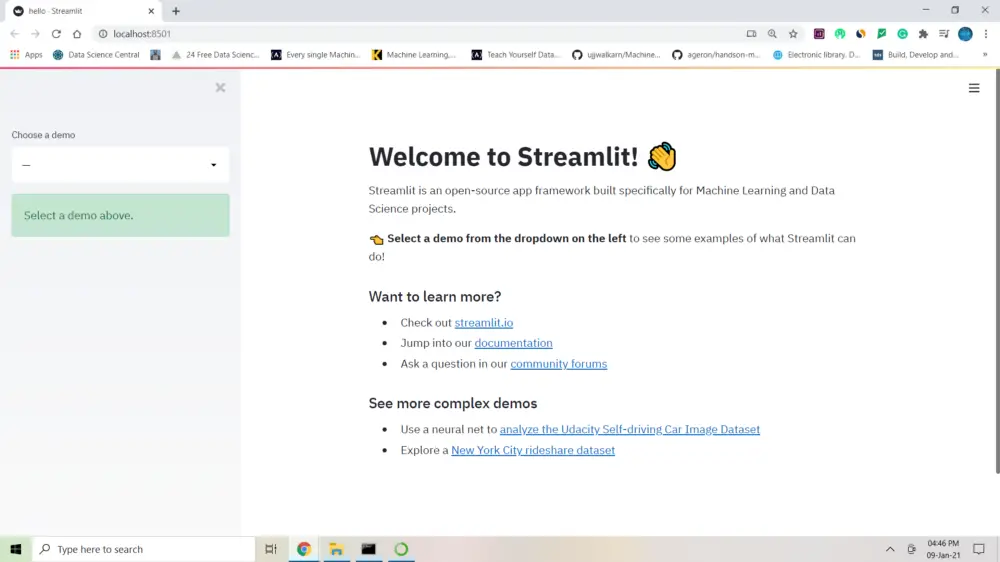
If the installation is successful, you will see the below message on the command prompt, and also the new window will be opened with an address pointing to http://localhost:8501/. This confirms the successful installation of Streamlit.
Transformers 🤗
Transformers needs no introduction. It provides hundreds of pre-trained models that we can use for many NLP tasks such as — classification, summarization, translation, text generation, etc. In this article, we will use T5 and BART models for summarization.
Installation
Complete Code
As you can see from the below code, it’s pretty straightforward and easy if you already know the basics of python.
- Import all the required libraries such as torch, streamlit, transformers, etc.
- Next, add the title and subheading to the page using streamlit’s
titleandmarkdownmethods. - Using
selectboxmethod you can select either BART or T5 model from the drop-down list. By default, BART is selected when you open the app. - Using
beta_columnsmethod, you can get 6 input parameters and pass them to the respective model. - Next, input text that needs to go through summarization is read from the screen using
text_areamethod. - Finally, once you click on
submit, the input text is passed to the functionrun_modelthat generates a summary and finally will get displayed on the screen.
import torch
import streamlit as st
from transformers import BartTokenizer, BartForConditionalGeneration
from transformers import T5Tokenizer, T5ForConditionalGeneration
st.title('Text Summarization Demo')
st.markdown('Using BART and T5 transformer model')
model = st.selectbox('Select the model', ('BART', 'T5'))
if model == 'BART':
_num_beams = 4
_no_repeat_ngram_size = 3
_length_penalty = 1
_min_length = 12
_max_length = 128
_early_stopping = True
else:
_num_beams = 4
_no_repeat_ngram_size = 3
_length_penalty = 2
_min_length = 30
_max_length = 200
_early_stopping = True
col1, col2, col3 = st.beta_columns(3)
_num_beams = col1.number_input("num_beams", value=_num_beams)
_no_repeat_ngram_size = col2.number_input("no_repeat_ngram_size", value=_no_repeat_ngram_size)
_length_penalty = col3.number_input("length_penalty", value=_length_penalty)
col1, col2, col3 = st.beta_columns(3)
_min_length = col1.number_input("min_length", value=_min_length)
_max_length = col2.number_input("max_length", value=_max_length)
_early_stopping = col3.number_input("early_stopping", value=_early_stopping)
text = st.text_area('Text Input')
def run_model(input_text):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if model == "BART":
bart_model = BartForConditionalGeneration.from_pretrained("facebook/bart-base")
bart_tokenizer = BartTokenizer.from_pretrained("facebook/bart-base")
input_text = str(input_text)
input_text = ' '.join(input_text.split())
input_tokenized = bart_tokenizer.encode(input_text, return_tensors='pt').to(device)
summary_ids = bart_model.generate(input_tokenized,
num_beams=_num_beams,
no_repeat_ngram_size=_no_repeat_ngram_size,
length_penalty=_length_penalty,
min_length=_min_length,
max_length=_max_length,
early_stopping=_early_stopping)
output = [bart_tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g insummary_ids]
st.write('Summary')
st.success(output[0])
else:
t5_model = T5ForConditionalGeneration.from_pretrained("t5-base")
t5_tokenizer = T5Tokenizer.from_pretrained("t5-base")
input_text = str(input_text).replace('\n', '')
input_text = ' '.join(input_text.split())
input_tokenized = t5_tokenizer.encode(input_text, return_tensors="pt").to(device)
summary_task = torch.tensor([[21603, 10]]).to(device)
input_tokenized = torch.cat([summary_task, input_tokenized], dim=-1).to(device)
summary_ids = t5_model.generate(input_tokenized,
num_beams=_num_beams,
no_repeat_ngram_size=_no_repeat_ngram_size,
length_penalty=_length_penalty,
min_length=_min_length,
max_length=_max_length,
early_stopping=_early_stopping)
output = [t5_tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=False) for g in summary_ids]
st.write('Summary')
st.success(output[0])
if st.button('Submit'):
run_model(text)
To create an app run the below command and you should be able to see the below summarization app. Now, you can play around with both the models and tuning the parameters to generate summaries.
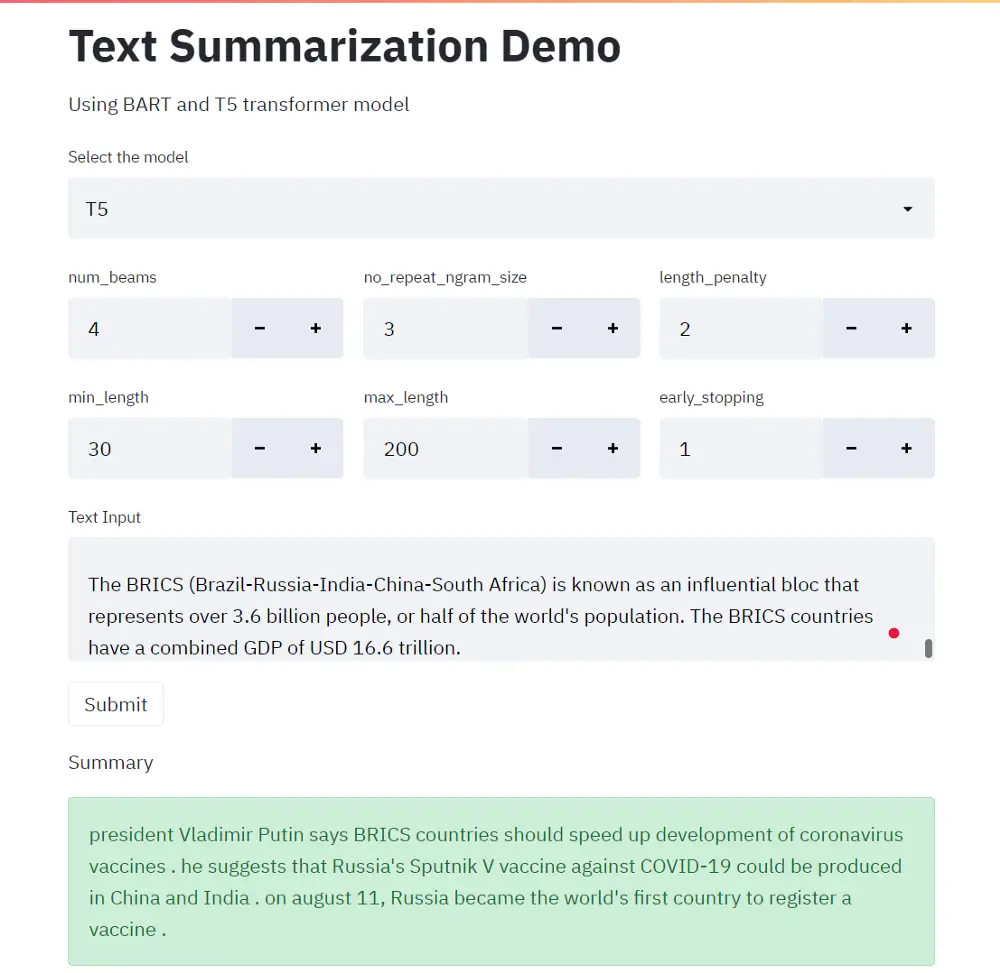
Conclusion
In this article, you have understood how to use Streamlit to create ML apps faster. Here, I only covered a few features of Streamlit but there are many more cool features available for creating beautiful ML apps. So, if you haven’t tried Streamlit yet, I strongly suggest you explore it today and I am sure you will not regret learning it. Happy Learning !!
