

Introduction
In the previous article here, we have covered what is Elasticsearch, why we should use it, its competitors, use cases, etc. In this article we will go through the Elasticsearch core concepts such as nodes, clusters, indices, sharding, documents, routing, and replication. This will help further help you understand how Elasticsearch works that will be covered in future articles.
The below diagram will help you understand the concepts as go through rest of the article.
Node
Elasticsearch runs on Java Virtual Machines (JVM). Each JVM instance running Elasticsearch can be considered as an Elasticsearch node.
Whenever we start an Elasticsearch instance we are starting a node. If you are running a single node, then you have a cluster of only one node. But in real life, a cluster will have a number of nodes.
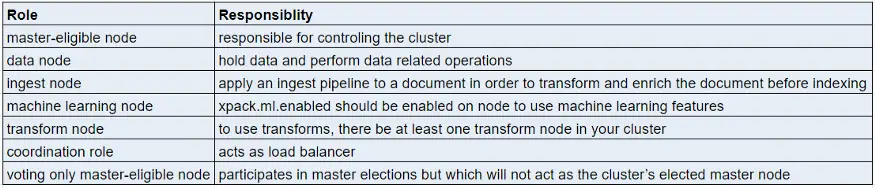
Nodes can play different roles such as master-eligible, data, ingest, machine learning, transform & coordination. These node roles are configured by setting node.roles. If the node roles are not configured then each node has the following roles by default: master, data, ingest, ml.
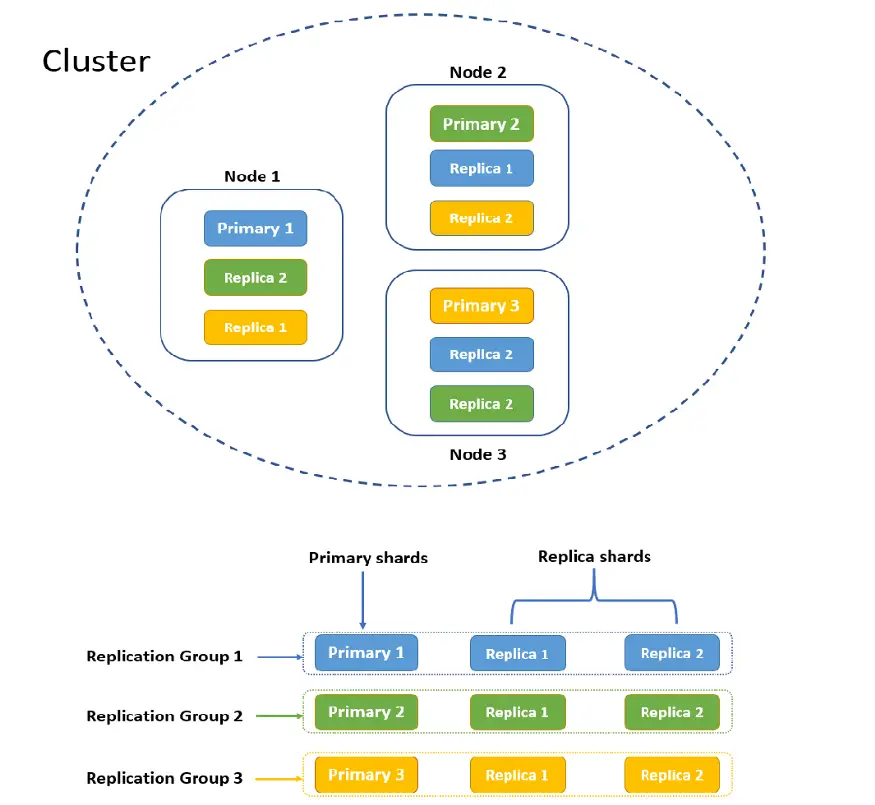
Cluster
A cluster is a collection of one or more Elasticsearch nodes that are running on one or more machines (virtual or physical). By default, the cluster name will be elasticsearch that can be changed as needed.
We can set up nodes on a single machine or on different machines. In a production environment, we would set up nodes on different machines in order to achieve high availability. In a non-production environment, we may set up multiple nodes on the same machine, but we may not be able to test the high-availability feature.
We can add or remove the nodes from the cluster and as it happens cluster automatically re-organizes and distributes data evenly across all the nodes. As discussed above, each node in the cluster have a designated role.
Any changes to the default setting of the cluster are configured from the elasticsearch.yml file.
Document
A document is a JSON object which is stored in Elasticsearch. This is analogous to rows/records in RDBMS systems. JSON objects contain zero or more key-value pairs.
Each document is stored in an index and has an id. This id is assigned by Elasticsearch if not specified. Refer to the sample document below after indexing.
{
"name" : "Python Simplified",
"authors" : Chetan Ambi, Swathi Ambi",
"language" : "English",
"founded" : 2020
}
Index
An index is analogous to a database in relational database systems (RDBMS). Each document in Elasticsearch is stored within an index and the index is a collection of documents with similar characteristics.
You can have as many indices defined in Elasticsearch as you want. For example, a customer index for storing customer information and a demographics index for storing customers’ demographics information, etc.
Sharding
The process of splitting the index into multiple pieces is called sharding. These multiple pieces can be stored in the same node or different node within the cluster.
By default, the index will have one shard. Once an index is created we can not change the value of the number of shards. This is because Routing (discussed below) uses a number of shards so if we were to change the number of shards it will result in identifying wrong shards for processing. Also, the number of shards depends on the requirement or use case.
Why do we need sharding — We know that data is stored in the index. Since there is no limit on the number of the document that can be stored in the index, it can try to grow in size beyond the capacity of the server. That is the main reason why Elasticsearch indexing starts failing. In order to overcome this, sharding is introduced.
Replication
Replication is the process of creating multiple copies of shards and these copies are called replica shards. Shards that have been replicated are called primary shards. The primary shards & the replica shards are together termed as replication groups. To ensure high availability, replica shards are not stored on the same node.
The default value of the number of shards is 1 but it can be modified anytime. We need to make sure that we not using too few or too many shards as it will impact the performance and speed.
Routing
All the data is stored in primary shards. A document you are looking for is stored in any one of the primary shards. Routing the process of determining which shard that document will reside in.
The default routing settings work best and make sure that documents are evenly distributed across the shards. The default routing method uses _id of the document to find a shard. This is applicable to both user-provided _ids and randomly generated _ids by Elasticsearch.
When we need custom routing
Elasticsearch also provides the option to use custom routing . Consider an index with 20–25 shards. When the search request comes to node looking for a document, Elasticsearch doesn’t know how to find the node that has the requested data. So the node will broadcast the request to all the shards in the index. Now each shard will perform a search query and sends the response back to the node. Finally, responses from all the shards are merged on a dedicated node, sorted, and then sent to the user.
This will potentially lead the performance issues. In order to avoid this potential problem, Elasticsearch provides the option to use custom routing. With this option instead of broadcasting the search request to all the shards, you can directly look in a particular shard. Routing ensures that all documents with the same routing value will locate to the same shard, eliminating the need to broadcast searches.
Conclusion
In this article, we have covered the key concepts in Elasticsearch such as nodes, clusters, indices, sharding, documents, routing, and replication. I hope you find this article useful.
