

Introduction
Pandas is the most popular library in the Python ecosystem for any data analysis task. We have been using it regularly with Python.
It’s a great tool when the dataset is small say less than 2–3 GB. But when the size of the dataset increases beyond 2–3 GB it is not recommended to use Pandas.
Pandas loads the entire data into memory before doing any processing on the dataframe. So, if the size of the dataset is larger than the memory, you will run into memory errors. Hence, Pandas is not suitable for larger than the memory datasets.
Sometimes even when the dataset is smaller than memory we still get into memory issues. Because during the preprocessing and transformation Pandas creates a copy of the dataframe thereby increasing the memory footprint which then causes memory errors.
Since you are reading this article, I assume you probably want to use Pandas for a rich set of features even though the dataset is large.
But, is it possible to use Pandas on larger than memory datasets? The answer is YES. You can handle large datasets in python using Pandas with some techniques. BUT, up to a certain extent.
Let’s see some techniques on how to handle larger datasets in Python using Pandas. These techniques will help you process millions of records in Python.
Techniques to handle large datasets
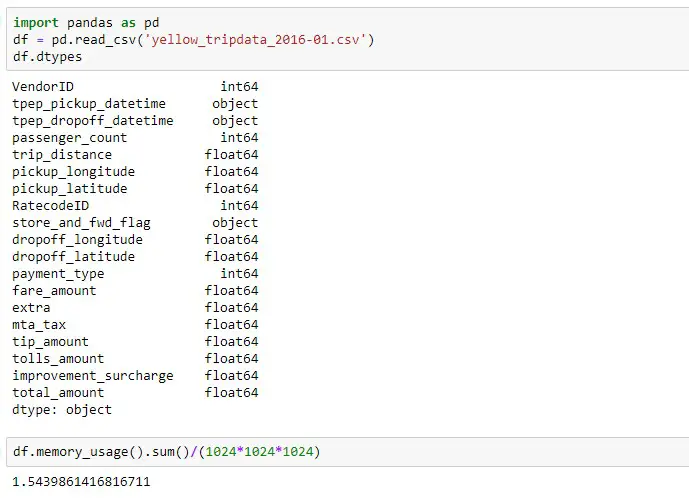
We will be using NYC Yellow Taxi Trip Data for the year 2016. The size of the dataset is around 1.5 GB which is good enough to explain the below techniques.
1. Use efficient data types
When you load the dataset into pandas dataframe, the default datatypes assigned to each column are not memory efficient.
If we can convert these data types into memory-efficient ones we can save a lot of memory. For example, int64 can be downcast to int8 or int16 or int32 depending upon the max and min value the column holds.
The below code takes of this downcasting for all numeric datatypes excluding object and DateTime types.

As you can see from the below result, the size of the dataset is drastically reduced, about 60%, after downcasting the data types of columns. In the 2nd screenshot, you can see that data types are changed to int8 or float16 or float 32.

What happened here actually? Let’s take a column named passenger_count as an example. It holds values 0, 1, 2, 3, 4, 5, 6, 7, 8, 9. The default data type was int64. Do you need 64 bits to store these 10 values? No. 8 bits or 1 byte is enough to hold these values. Hence it will be down-casted into int8. Similar logic goes into other numeric data types.
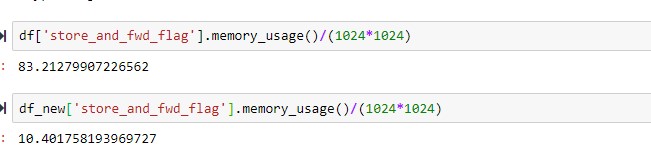
What about “object” data type? converting object data type to a category can also save a lot of memory. For the given dataset, store_and_fwd_flag was converted to category type.
As you can see from the below screenshot, the size of the columns reduced from 83 Mb to just 10 MB.
2. Remove unwanted columns
Sometimes you don’t need all the columns/features for your analysis. In such situations, you don’t have to load the dataset into pandas dataframe and then delete it.
Instead, you can exclude the columns while loading the dataframe. This method along with the efficient data type can save reduce the size of the dataframe significantly.
3. Chunking
Do you know Pandas read_csv, read_excel, etc. have chunksize parameter that can be used to read larger than the memory datasets?
When you use chunksize parameter, it returns an iterable object of the type TextFileReader. Next, as with any other iterable, you can iterate over this object until data is exhausted.
Refer to our article here to understand more about the iterables and iterators.
In the below example, we are using chucksize of 100,000. What this means is that Pandas reads 100,000 each time and returns iterable called reader. Now you can perform any operation on this reader object. Once the processing on this object is done, Pandas reads next 100,000 records and the process continues until all the records are processed.
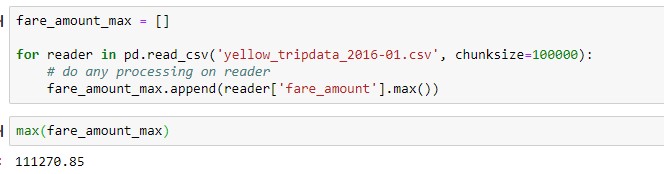
Note that this method of using chunksize is useful only when the operation you are performing doesn’t require coordination between the chunks.
Code
4. Pandas alternatives
Pandas dataframe API has become so popular that there are so many libraries out there for handling out-of-memory datasets more efficiently than Pandas.
Below is the list of most popular packages for handling larger than memory data in Python. We will not be able to cover all these in detail. The readers are requested to go through the documentation mentioned below. However, we will be covering these libraries in detail in future articles.
a. Dask
Dask makes use of parallel processing which helps in faster computation, processing larger than memory data, and making use of all available resources.
b. Ray
Ray was developed by researchers at Berkeley with existing Pandas users in mind. Ray also makes use of multiprocessing and it also helps deal with larger than memory data.
c. Modin
Modinis a drop-in replacement for Pandas. It’s no different than Dask and Ray wrt multi-threading and multi-processing features. Modin works really well with larger than memory data.
d. Vaex
Vaex is yet another Pandas like library that makes use of multi-threading and multi-processing.
