

Introduction
If you are looking for a database for storing your machine learning models then this article is for you. You can use MongoDB to store and retrieve your machine learning models. Without further adieu let’s get started.
MongoDB
MongoDB is a very popular NoSQL database. In MongoDB, the data is stored in the form of JSON-like documents. More specifically, documents are stored in the form of a BSON object which is nothing but binary data represented in JSON format.
The documents and collections in MongoDB are analogous to records and tables in relational database (RDBMS) respectively.
If you are already using MongoDB then you must be aware that the BSON document has a size limit of 16 MB. Meaning you can’t store the file if it’s more than 16 MB in size. What this also means for you is that you can’t use MongoDB document storage if your machine learning model size is more than 16 MB.
Store & Retrieve Model from MongoDB
Refer to the below example for storing and retrieving from MongoDB when the model size is less than 16 MB.
from bson.binary import Binary
from bson import ObjectId
import pymongo, gridfs
from gridfs import GridFS
from pymongo import MongoClient
MONGO_HOST = "127.0.0.1"
MONGO_PORT = 27017
MONGO_DB = "myDB"
model_file = 'keras_model.h5'
myclient = pymongo.MongoClient(MONGO_HOST, MONGO_PORT)
mydb = myclient[MONGO_DB]
mycol = mydb['mycollection']
# Store model as binary document
with open(model_file, "rb") as f:
encoded = Binary(f.read())
mycol.insert_one({"filename": model_file, "file": encoded, "description": "Keras model" })
# Retrieve and store the ML model from MongoDB
data = mycol.find_one({'filename': 'keras_model.h5'})
with open("keras_model_fromMongo.h5", "wb") as f:
f.write(data['file'])
As shown in the below screenshot from MongoDB Compass, keras_model.h5 file is stored successfully into MongoDB. Note that the model size is less than 16 MB. If it exceeds more than 16 MB, you will run into error.
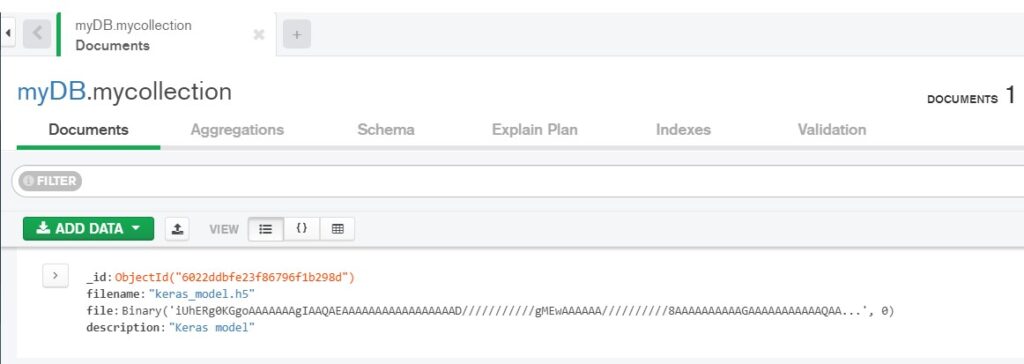
I know what you must be thinking. What if the model size is more than 16 MB. That’s a valid question. Not to be surprised, sometimes model size will be in gigabytes (e.g. transformer models). In such situations, MongoDB provides GridFS API that can be used for storing documents that are larger than 16 MB. Let’s take look at GridFS in the next section.
GridFS
GridFS is a file system for storing and retrieving documents that are larger than the 16 MB size limit of the BSON document. It can also be used even if the size of the file is less than 16 MB.
How GridFS stores data
GridFS divides the file into what are called chunks and each chunk is stored separately as a document. By default, each chuck is of the size 255 KB. Only the last chunk can be 255 KB or smaller.
GridFS makes use of two collections (tables) chunks and files to store the file. As you can see from the below diagram, GridFS appends these two collections to the default bucket fs.
- chunks: this collection stores all the chunks that contain data in the binary format.
- files: this collection stores metadata of the file.
The main goal of this article to use GridFS for storing & retrieving the machine learning models. So, let’s look into some code now.
Store ML model using GridFS
First, you need to import the required libraries and initialize a few variables such as MONGO_HOST, MONGO_PORT, and MONGO_DB. Next, you create the MongoClient object myclient that is used to connect to a specific database (‘mydb’ in this case). Then, a GridFS instance is created to run on top of a specific database. Finally, the put() method of the GridFS object is used to store the model into MongoDB.
Note that the put() method returns the ObjectId which is then used when retrieving the model from MongoDB.
import io
import pymongo, gridfs
from gridfs import GridFS
from pymongo import MongoClient
MONGO_HOST = "127.0.0.1"
MONGO_PORT = 27017
MONGO_DB = "mydb"
myclient = pymongo.MongoClient(MONGO_HOST, MONGO_PORT)
mydb = myclient[MONGO_DB]
fs = gridfs.GridFS(mydb)
model_name = 'tf_model.h5'
with io.FileIO(model_name, 'r') as fileObject:
docId = fs.put(fileObject, filename=model_name)
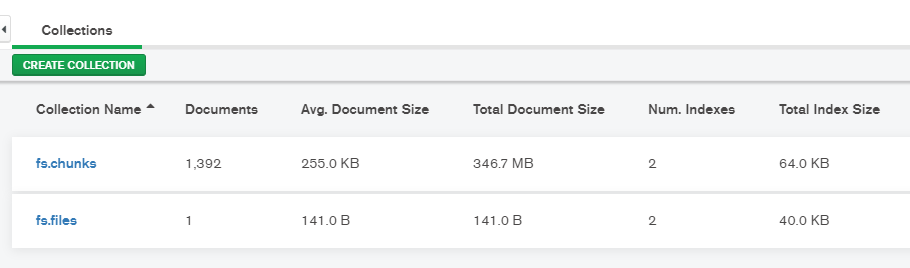
Once you run the above code, it will store tf_model.h5 model into MongoDB. As explained earlier, data is split into chunks and will get stored in fs.chunks and meta information will get stored in fs.files.
For the above example, tf_model.h5 is around 347 MB in size which is obviously greater than 16 MB. When this model was stored using GridFS, it was split into 1392 chunks and stored as documents. You are advised to explore the content of fs.chunks and fs.files to get an understanding of how.
Retrieve ML model using GridFS
To retrieve the ML model from MongoDB, you need to follow the same steps as earlier except for the last one. You need to pass the ObjectId of the file (model) you want to retrieve from MongoDB to the get() method of GridFS. This will download the model from MongoDB to the local machine as tf_model_fromMongo.h5.
import io
import pymongo, gridfs
from bson import ObjectId
MONGO_HOST = "127.0.0.1"
MONGO_PORT = 27017
MONGO_DB = "mydb"
con = pymongo.MongoClient(MONGO_HOST, MONGO_PORT)
db = con[MONGO_DB]
fs = gridfs.GridFS(db)
with open('tf_model_fromMongo.h5', 'wb') as fileObject:
fileObject.write(fs.get(ObjectId(docId))
.read() )
Note that the use of GridFS is not limited to storing and retrieving only machine learning models. You can use it to store any type file such as text files, images, videos, etc.
Conclusion
MongoDB BSON document has a size limit of 16 MB so it can not be used to store any document that is larger than this limit. You understood that using the GridFS API, you can store large objects, including machine learning models, into MongoDB. You also understood how to store and retrieve models from MongoDB with examples.
