

Introduction
When we are working on any NLP project or competition, we spend most of our time on preprocessing the text such as removing digits, punctuations, stopwords, whitespaces, etc. and sometimes visualization too. After experimenting TextHero on a couple of NLP datasets I found this library to be extremely useful for preprocessing and visualization. This will save us some time writing custom functions. Aren’t you excited!!? So let’s dive in.
We will apply techniques that we are going to learn in this article to Kaggle’s Spooky Author Identification dataset. You can find the dataset here. The complete code is given at the end of the article.
Texthero
Installation
pip install texthero
Preprocessing
As the name itself says clean method is used to clean the text. By default, the clean method applies 7 default pipelines to the text.
- fillna(s)
- lowercase(s)
- remove_digits()
- remove_punctuation()
- remove_diacritics()
- remove_stopwords()
- remove_whitespace()
from texthero import preprocessing
df['clean_text'] = preprocessing.clean(df['text'])
We can confirm the default pipelines used with the below code:
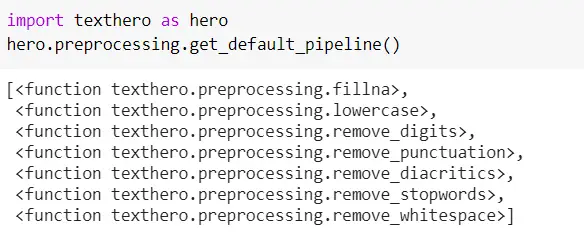
Apart from the above 7 default pipelines, TextHero provides many more pipelines that we can use. See the complete list here with descriptions. These are very useful as we deal with all these during text preprocessing.
Based on our requirements, we can also have our custom pipelines as shown below. Here in this example, we are using two pipelines. However, we can use as many pipelines as we want.
from texthero import preprocessing
custom_pipeline = [preprocessing.fillna, preprocessing.lowercase]
df['clean_text'] = preprocessing.clean(df['text'], custom_pipeline)
NLP
As of now, this NLP functionality provides only dependency_parse, named_entity, and noun_phrases methods. See the sample code below. I believe, more functionalities will be added later.
Named entity
s = pd.Series(“Narendra Damodardas Modi is an Indian politician serving as the 14th and current Prime Minister of India since 2014”)
print(nlp.named_entities(s)[0])
Output:
[('Narendra Damodardas Modi', 'PERSON', 0, 24),
('Indian', 'NORP', 31, 37),
('14th', 'ORDINAL', 64, 68),
('India', 'GPE', 99, 104),
('2014', 'DATE', 111, 115)]
Noun phrases
s = pd.Series(“Narendra Damodardas Modi is an Indian politician serving as the 14th and current Prime Minister of India since 2014”)
print(nlp.noun_chunks(s)[0])
Output:
[(‘Narendra Damodardas Modi’, ‘NP’, 0, 24),
(‘an Indian politician’, ‘NP’, 28, 48),
(‘the 14th and current Prime Minister’, ‘NP’, 60, 95),
(‘India’, ‘NP’, 99, 104)]
Representation
This functionality is used to map text data into vectors (Term Frequency, TF-IDF), for clustering (kmeans, dbscan, meanshift) and also for dimensionality reduction (PCA, t-SNE, NMF).
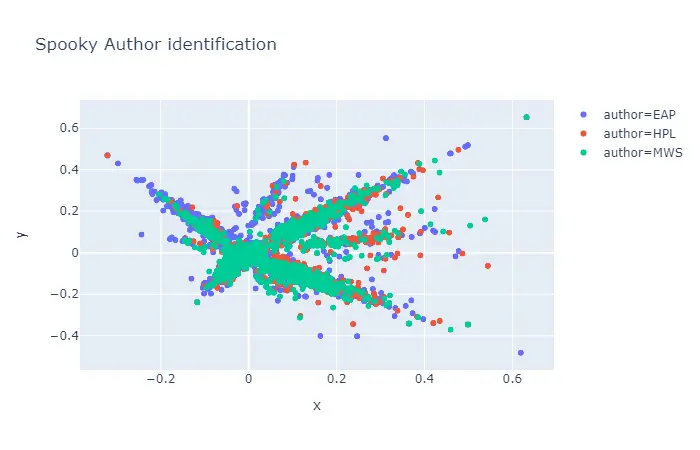
Let’s look at an example with TF-IDF and PCA on the Spooky author identification train dataset.
train['pca'] = (
train['text']
.pipe(preprocessing.clean)
.pipe(representation.tfidf, max_features=1000)
.pipe(representation.pca)
)
visualization.scatterplot(train, 'pca', color='author', title="Spooky Author identification")
Output:
Visualization
This functionality is used for plotting scatter-plots, word cloud, and also used to get top n words from the text. Refer to the examples below.
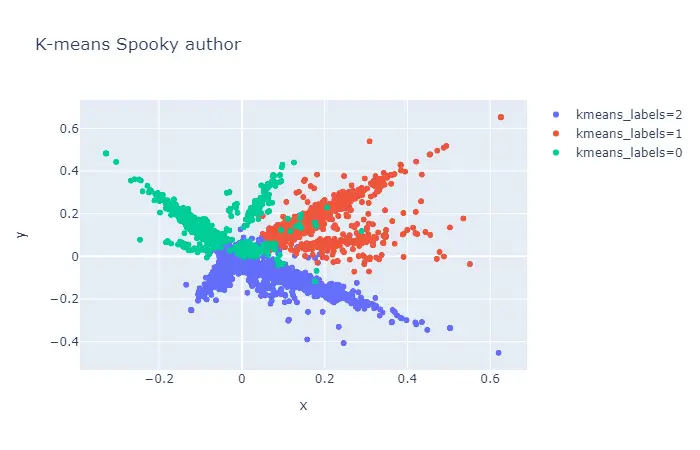
Scatter-plot example
train['tfidf'] = (
train['text']
.pipe(preprocessing.clean)
.pipe(representation.tfidf, max_features=1000)
)
train['kmeans_labels'] = (
train['tfidf']
.pipe(representation.kmeans, n_clusters=3)
.astype(str)
)
train['pca'] = train['tfidf'].pipe(representation.pca)
visualization.scatterplot(train, 'pca', color='kmeans_labels', title="K-means Spooky author")
Output:
Wordcloud example
from texthero import visualization
visualization.wordcloud(train['clean_text'])
Output:

Top words example
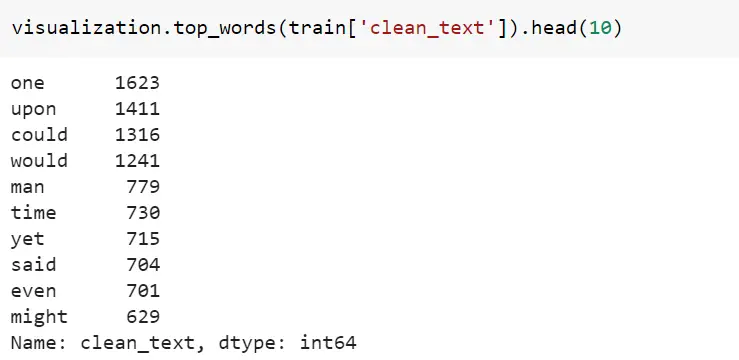
Code
Conclusion
We have gone thru most of the functionalities provided by TextHero. I found that most of the features are really useful which we can try to use them for the next NLP project for data cleaning/preprocessing and quick visualization of the data.
