

Imbalanced Data
One of the most common problems when working with classification tasks is imbalanced data where one class is dominating over the other. For example, in the Credit Card fraud detection task, there will be very few fraud transactions (positive class) when compared with non-fraud transactions (negative class). Sometimes, it is even possible that 99.99% of transactions will be non-fraud and only 0.01% of transactions will be fraud transactions.
You can have a class imbalance problem on binary classification tasks as well as multi-class classification tasks. However, the techniques we are going to learn here can be applied to both.
Why worry about Imbalanced Data?
Consider the same example of credit card fraud transaction detection where fraud and non-fraud transactions are in the ratio of 99% and 1% respectively. This is a highly imbalanced dataset. If you were to train the model on this dataset, you will get accuracy as high as 99% because the classifier will pick up the patterns in the popular classes and predict almost everything as non-fraud transactions.
As a result, the model will fail to generalize on the new data. This is also the reason why accuracy is not a good evaluation metric when dealing with imbalanced data.
Examples of Imbalanced Data
Here are some of the examples where we come across imbalanced data in machine learning:
- Fraud Detection
- Claim Prediction
- Churn Prediction
- Spam Detection
- Anomaly Detection
- Outlier Detection, etc.
Handling Imbalanced Data
Let’s try to go through some of the methods which are used to handle an imbalanced dataset. Note that here we are only mentioning the methods that can be used for handling imbalanced data. However, we plan to cover these with examples in future articles.
Get More Data
When you have imbalanced data, it’s good practice to check if it’s possible to get more data so as to reduce the class imbalance. In most of the cases, due to the nature of the problem you are trying to solve, you won’t get more data as needed.
Change Evaluation Metric
As we just discussed above, accuracy is not a good metric when dealing with imbalanced classes. There are other classification metrics that can provide better insights that are mentioned below. You can choose the metric based on the use case or problem you are trying to solve.
Precision: Out of all the positively predicted classes, what percentage of them were actually positive classes.
Recall: Recall is also called sensitivity and True Positive Rate (TPR). Out of all the positive classes, what percentage of them were actually predicted as positive.
F1-Score: F1-Score is a harmonic mean of Precision and Recall. The result ranges between 0 and 1, with 0 being the worst and 1 being the best. It is the measure of the model’s accuracy.
ROC-AUC: ROC curve (Receiver Operating Characteristic curve) is a graph showing the performance of a classification model at different probability thresholds. ROC graph is created by plotting FPR Vs. TPR where FPR (False Positive Rate) is plotted on the x-axis and TPR (True Positive Rate) is plotted on the y-axis for different probability threshold values ranging from 0.0 to 1.0.
Change the Algorithms
You should try and compare the results with different machine learning algorithms. Tree-based classifiers such as Decision Tree classifiers, Extra Tree classifier, Random Forest classifier, etc. perform well even with an imbalanced dataset.
Resampling Techniques
It is the method of balancing majority and minority classes in the dataset. There are two resampling techniques:
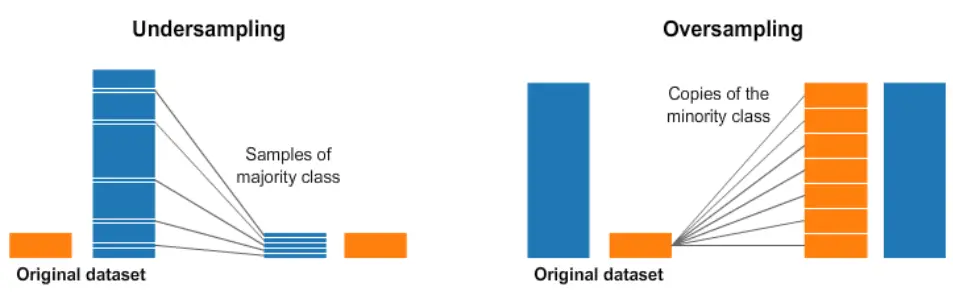
Under Sampling — it helps to reduce the number of majority class examples in the dataset. Since we are removing majority class examples from the original data, some of the information is lost.
Over Sampling — it helps to increase the number of minority class examples in the dataset. One of the main advantages of oversampling is no information is lost from both the majority and minority classes during the process. It is prone to overfitting.
Generate Synthetic Samples
Over Sampling technique creates copies of minority classes to balance the dataset. An improvement of this method is to synthesize new minority classes using different approaches. Two of the most commonly used techniques are — SMOTE (Synthetic Minority Over-Sampling Technique) and ADASYN (Adaptive Synthetic sampling).
Conclusion
In this article, you have understood what is class imbalance and 5 common techniques to deal with imbalanced data in Machine Learning. In the future articles, we will cover these techniques with examples.
I am curious to know how you handle imbalanced data in your machine learning project. Please let me know in the comments section.
Originally published at Medium on Oct 17, 2020
