

Introduction
Every Pandas beginner has probably wondered how to iterate over rows in a Pandas DataFrame. And I’m not an exception!!
You want to perform some processing on each row element. You’ll need to iterate over rows in a DataFrame to accomplish this. So, how do you go about it? What are the various iteration methods, and which one is the most efficient? All of this will be covered in the article. Let’s get started.
Do you have to iterate over rows in a DataFrame?
Well, if you’re looking for a way to iterate over a row in a Pandas DataFrame, I have a nasty answer for you. It is considered an anti-pattern and is not a best practice. Even the panda’s documentation warns about it.
"Iterating through pandas objects is generally slow. In many cases, iterating manually over the rows is not needed and can be avoided"
You should consider iterating over rows in a Pandas DataFrame only if you are working with a small dataset (thousands of rows), performance is not an issue, and you have already considered the following options:
- Vectorization: Whenever possible, use vectorized operations such as NumPy methods and built-in functions. Vectorized operations can be 100 to 200 times faster than non-vectorized operations. Therefore, if time is important, consider vectorization.
- Apply method: The apply () method is also useful in many situations. It is highly optimized for accessing rows in the Pandas DataFrame.
- Cython function: If the performance is of great importance then you should explore Cython, Numba, and pandas.eval(). Refer to enhancing the performance.
Now let’s talk about the main topic in this article. Note that. the Jupyter notebook code is also included at the end of each section.
Different methods to iterate over a DataFrame
As mentioned earlier, these methods work well when working with small datasets, and speed doesn’t matter. However, if you are working with medium to large datasets, you should avoid these techniques and try other techniques such as vectorization and apply method application.
In this section, you will look at the flight dataset in the Seaborn library.
import seaborn as sns
df = sns.load_dataset('flights').head(2)
print(df.to_markdown())
| | year | month | passengers |
|---:|-------:|:--------|-------------:|
| 0 | 1949 | Jan | 112 |
| 1 | 1949 | Feb | 118 |
1. iterrows() method
The iterrows() method loops through each row in the DataFrame and returns index and data pair where —
index — index of the DataFrame
data — row is returned as series.
You need to reference the column name to access the row value. See the example below.
for idx, row in df.iterrows():
print(row['year'], row['month'], row['passengers'])
# Output:
# 1949 January 112
# 1949 February 118
NOTES:
1. The iterrows() method does not preserve the datatype across the rows. This is because each row is returned as a series and data type is inferred differently. If you want to data type to be preserved then you need to check itertuples() method described below.
2. You should avoid modifying something you are iterating over. This is because iterrows() returns an iterator which returns a copy of the object. Therefore, any changes made to this copied object will not affect the original object.
2. itertuples() method
The itertuples() method iterate over each row in a DataFrame returns namedtuple object.
DataFrame.itertuples(index=True, name='Pandas')
where –
index — if the index is True then the returned namedtuple includes the DataFrame index as the first element. The default is True.
name — it is the name of the namedtuple. The default is ‘Pandas’.
The below example shows how to iterate over DataFrame using itertuples and it also shows that the itertuples returns namedtuple.
The itertuples() method is comparatively faster than iterrows() method. So if you had to choose between the two you should go with itertuples.
for row in df.itertuples():
print(row.year, row.month, row.passengers)
# Output:
# 1949 January 112
# 1949 February 118
Both iterrows() and itertuples() are Pandas recommended the approaches to iterate over rows in a DataFrame. However, there are other approaches as well. Let’s discover the other methods.
3. loc[] method
The loc method is a familiar method to all Pandas developers. Here is the syntax for the loc method.
dataframe.loc[<row selection>, <column selection>]</column></row>
You can access row elements using the loc method as shown in the below example. The row index value and column name should be passed to loc respectively to access row elements.
for idx in range(len(df)):
print(df.loc[idx, "year"], df.loc[idx, "month"], df.loc[idx, 'passengers'])
# Output:
# 1949 January 112
# 1949 February 118
4. iloc[] method
Like the loc method, iloc method is also a known method. Refer to the example below on how you can use iloc method to iterate over rows in a DataFrame. The row index and column index values are passed to iloc method to access the raw data.
for idx in range(len(df)):
print(df.iloc[idx, 0], df.iloc[idx, 1], df.iloc[idx, 2])
# Output:
# 1949 January 112
# 1949 February 118
5. index
You can also iterate over rows in a DataFrame using the index method as shown below. The code is self-explanatory.
for idx in df.index:
print(df['year'][idx], df['month'][idx], df['passengers'][idx])
# Output:
# 1949 January 112
# 1949 February 118
6. to_dict() method
Another method is to use to_dict() with orient=’records’ parameter you can iterate through rows in a DataFrame. Refer to the below self-explanatory code.
for item in df.to_dict(orient='records'):
print(item['year'], item['month'], item['passengers'])
# Output:
# 1949 January 112
# 1949 February 118
7. to_numpy() method
The to_numpy() method was first introduced in version Pandas 1.1.0. So, make sure you are using the latest version of Pandas to use this method. Refer to the example to see how to use to_numpy() to iterate over rows in a DataFrame.
for item in df.to_numpy():
print(item[0], item[1], item[2])
# Output:
# 1949 January 112
# 1949 February 118
8. iteritems & items()
Both iteritems() and items() behave exactly the same and they both iterate over the column name, Series pairs. By transposing the DataFrame before applying these methods, we can iterate over rows as shown in the below examples.
for key, value in df.T.iteritems():
print(value.year, value.month, value.passengers)
# Output:
# 1949 January 112
# 1949 February 118
for key, value in df.T.items():
print(value.year, value.month, value.passengers)
# Output:
# 1949 January 112
# 1949 February 118
Jupyter notebook code for the above section –
Speed comparison
We went through 8 methods of iterating over rows in Pandas DataFrame. Let’s compare which one is faster.
For this speed comparison, we are going to use the Suicides in India dataset from Kaggle. The dataset contains around 230,000 records. We will be doing any operation on the data but simply access each element in the row. We have used %%timeit magic function to estimate the time taken for each method.
Code for speed comparison –
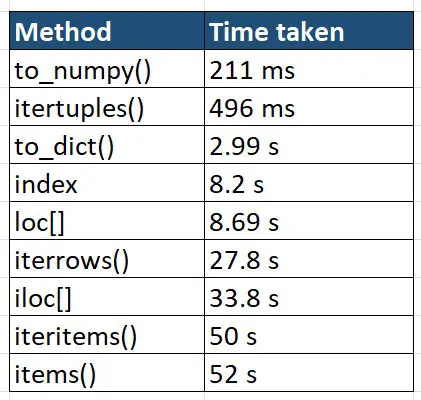
The results are shown below. The to_numpy() method wins the race with 211 ms. It’s almost 3 times faster than itertuples() method. The iterrows(), items(), iteritems() and iloc[] took much longer time for just 230,000 records.
If you are using millions of records then to_numpy() and itertuples() must be your go-to options. Otherwise, you will have to consider the alternate options that we discussed in the previous section if time and memory are the concern.
Summary
- You should not try to iterate over rows in Pandas DataFrame as it is considered an anti-pattern and not recommended. Even Pandas’ documentation suggests the same.
- If you are dealing with small datasets and time is not a constrain then you can explore the methods such as — iterrows(), itertuples(), loc[], iloc[], to_numpy(), to_dict(), items(), iteritems(), and index.
- If you are dealing with large datasets and time is the essence then consider exploring vectorization methods & built-in functions, apply() method and Cython, Numba, etc.
- Based on the speed performance results, to_numpy() runs much faster than all the methods. And itertuples() also not far behind and can be the next option.
