

Introduction
Feature scaling is one of the important steps in the machine learning pipeline. The two common techniques used for feature scaling are normalization and standardization. But, what is the difference between normalization and standardization? When should you use normalization and standardization? This is a very common question among people who just started their data science journey. Let’s try to answer these questions in the article.
You can find the code accompanying this article at Gist here and also at the end of the blog post.
What is feature scaling and why it is important?
Feature scaling is a method to transform data in the common range — [0, 1] or [-1, 1] or [-2, 2], etc. If the feature scaling is not applied to the data, then machine learning models give higher weightage to the features with large values, resulting in a biased model.
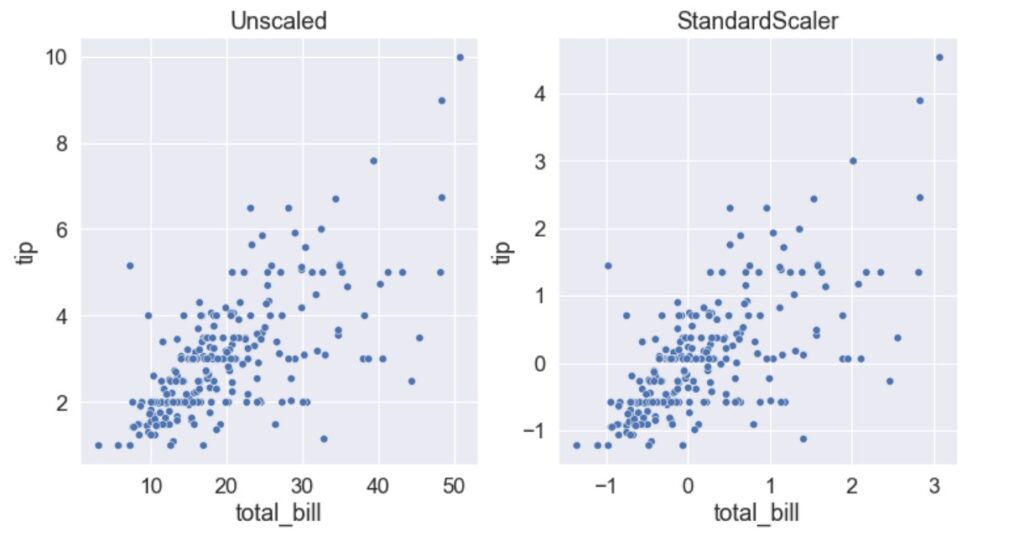
For example, let’s consider 2 features — total_bill and tip. As you can see both the features are in different ranges. The model only looks at the numbers. It doesn’t know which is total_bill or tip. When you build the model without feature scaling, the model will have a bias towards the features with larger values resulting in a biased model. To mitigate this issue we need to use feature scaling to the data.
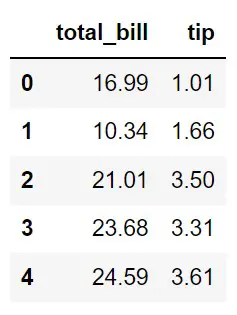
Before we start the discussion on normalization and standardization, let’s import the required libraries and the tips dataset from Seaborn. As you see total bill and tip values are in different range. We’ll use both features for normalization and standardization examples.
Normalization
Normalization is a feature scaling technique to bring the features in the data to a common range say [0, 1] or [-1, 0] or [-1, 1]. In this section, we’ll go through 3 popular normalization methods as discussed below.
MinMaxScaler
This method scales each feature individually such that it is in the range [0,1]. Each feature value is subtracted with the min value and divided by the difference between max and min.
It uses the minimum and maximum values for scaling and both minimum & maximum are sensitive to outliers. As a result, the MinMaxScaler method is also sensitive to outliers. Note that MinMaxScaler doesn’t change the distribution of the data.
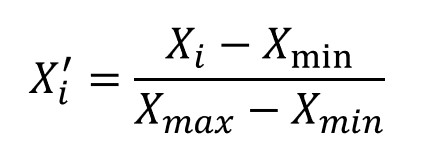
Scikit-learn implementation
You can use MinMaxScaler from Sklearn as shown below.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
minmaxscaler_df = pd.DataFrame(scaler.fit_transform(df), columns=df.columns)
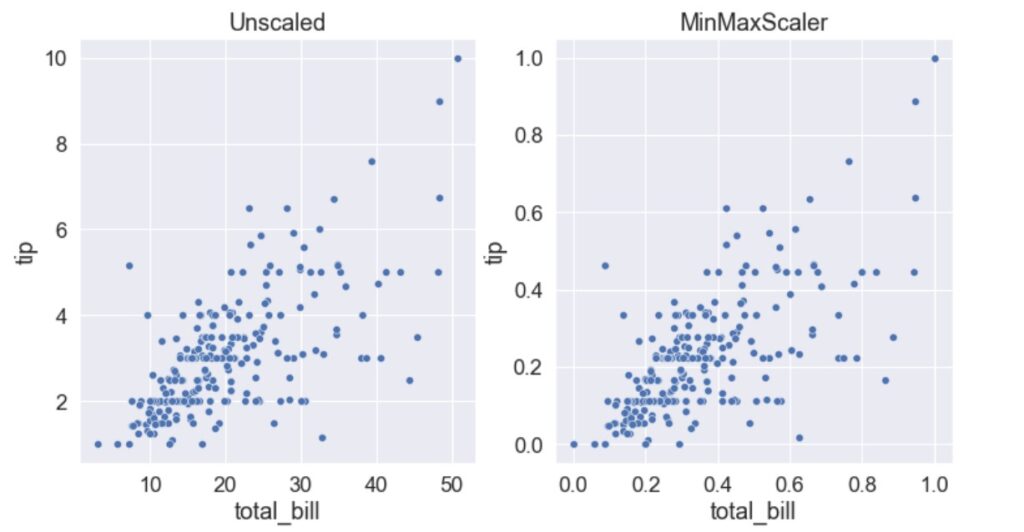
When to use MinMaxScaler?
- MinMaxScaler is preferred when the distribution of the features is unknown (i.e. if the features are not normally distributed).
- MinMaxScaler can also be considered if the underlying machine learning algorithms you are using don’t make any assumptions about the distribution of the data (eg. kNN, Neural Nets, etc.).
- Consider using MinMaxScaler only if features have very few or no outliers.
MaxAbsScaler
MaxAbsScaler is another normalization technique and this method scales each feature individually such that it is in the range [0, 1] or [-1, 0] or [-1, 1] under different scenarios as mentioned below.
- only positive values: [0, 1]
- only negative values: [-1, 0]
- both positive & negative values: [-1, 1]
In this method, each feature value is divided by the maximum absolute value. Since this method uses the maximum and hence it is also sensitive to outliers like MinMaxScaler.
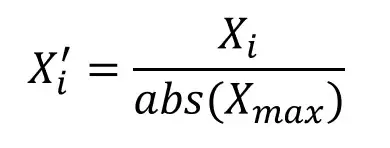
Scikit-learn implementation
You can use MaxAbsScaler from Sklearn as shown below.
from sklearn.preprocessing import MaxAbsScaler
scaler = MaxAbsScaler()
maxabsscaler_df = pd.DataFrame(scaler.fit_transform(df), columns = df.columns)
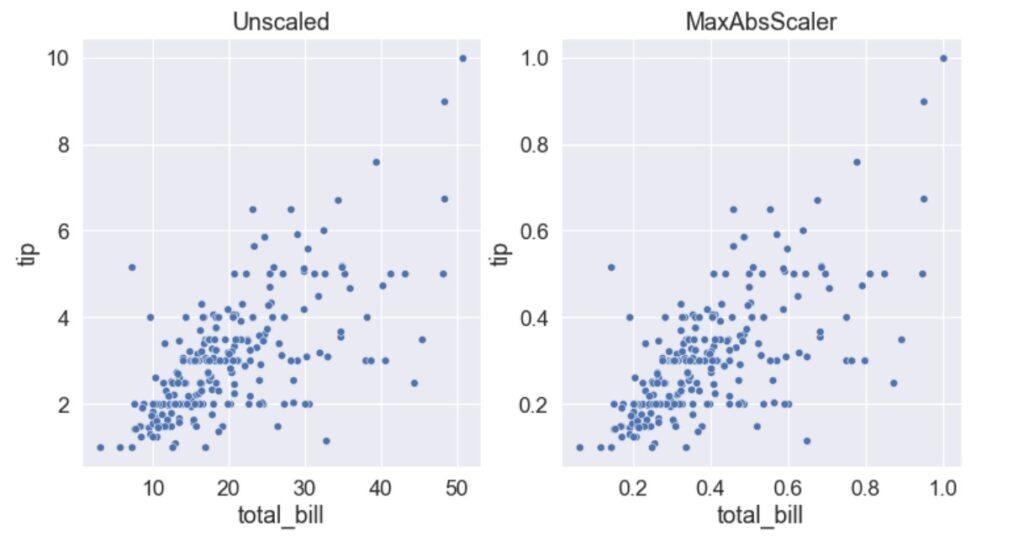
When to use MaxAbsScaler?
- If the data is sparse (i.e. most of the values are zeroes) you must consider using MaxAbsScaler. In fact, MaxAbsScaler is designed specifically for sparse data.
To curious minds — Why should you use MaxAbsScaler if the dataset is sparse? Please read this article by Christian Versloot here to understand.
RobustScaler
The MinMaxScaler and MaxAbsScaler are sensitive to outliers. So, the alternative is RobustScaler. Instead of using the minimum and maximum values as in MinMaxScaler or MaxAbsScaler, the RobustScaler uses IQR hence it is robust to outliers.
The formula for RobustScaler calculation is shown below. As you can see, the median is removed from the data points and scaled according to IQR (Inter Quartile Range). The calculated median and IQR are stored so that they can be used during the transformation on the test set. The scaling happens independently for each feature.
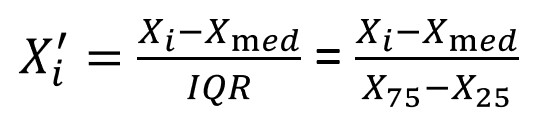
Scikit-learn implementation
You can use RobustScaler from Sklearn as shown below.
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
robustscaler_df = pd.DataFrame(scaler.fit_transform(df), columns = df.columns)
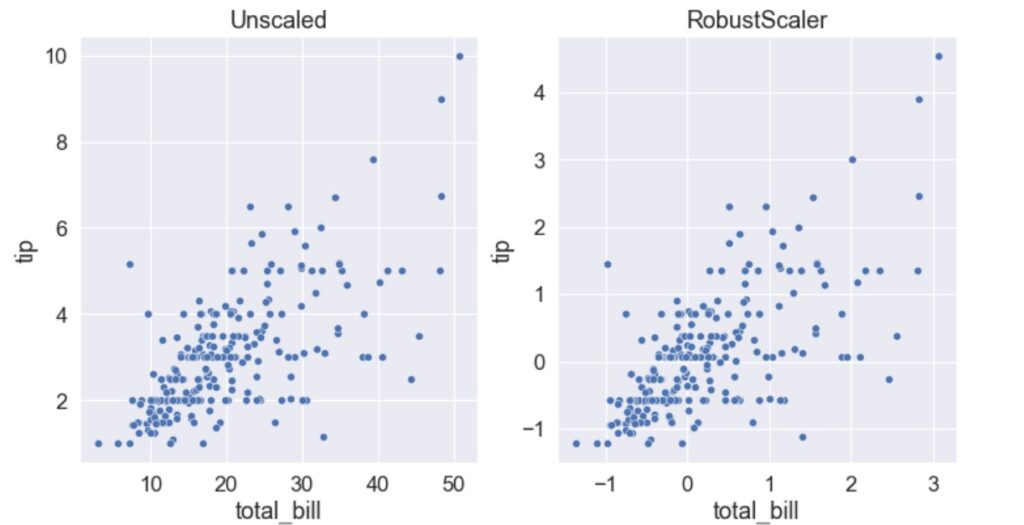
When to use RobustScaler?
- RobustScaler is preferred when the data contains outliers as it is less sensitive to outliers than MinMaxScaler and MaxAbsScaler.
Standardization
Standardization is the most commonly used feature scaling technique in machine learning. This is because some of the algorithms assume the normal or near-normal distribution of the data. If the features are normally distributed then the model behaves badly. The StandardScaler and standardization both refer to the same thing.
StandardScaler
This method removes the mean and scales the data with unit variance ( or standard deviation). The calculated mean and standard deviation are stored so that they can be used during the transformation of the test set. The scaling happens independently for each feature in the data.
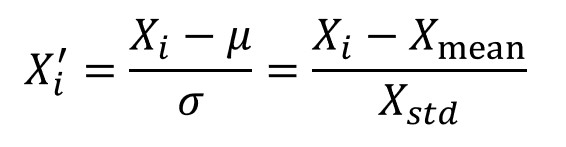
Scikit-learn implementation
You can use StandardScaler from Sklearn as shown below.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
standardscaler_df = pd.DataFrame(scaler.fit_transform(df), columns = df.columns)
The StandardScaler uses mean and mean is sensitive to outliers. Hence, outliers have an influence on the StandardScaler.
When to use StandardScaler?
- If the features are normally distributed then StandardScaler will be your first choice.
- Consider using StandardScaler if the underlying machine learning algorithms you are using make assumptions about the normal distribution of the data (eg. linear regression, logistic regression, etc.)
- If there are outliers in the data, then you can remove those outliers and use either MinMaxScaler/MaxAbsScaler/StandardScaler.
Code
Summary
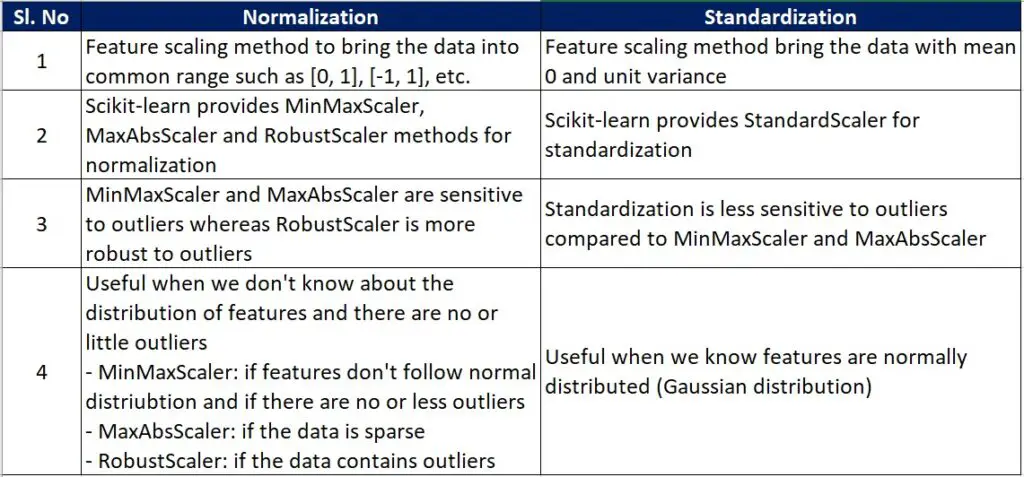
Normalization and Standardization are the two popular feature scaling techniques. The below table gives the summary of both methods.
However, note that feature scaling is not mandatory for all the algorithms. The tree-based algorithms such as the Decision Tree algorithm, Random Forest algorithm, Gradient Boosted Trees, etc. don’t need feature scaling.
References
[1]. https://scikit-learn.org/stable/modules/preprocessing.html
[2]. https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html
[3]. https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MaxAbsScaler.html
[4]. https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.RobustScaler.html
