

Introduction
The machine learning algorithms do not like categorical (non-numeric) variables. You have to convert them to numeric features before building your model. This process of converting categorical features into numeric features is known as categorical data encoding. There are many encoding techniques available but the most common and widely used technique is One Hot Encoding.
The popular Python machine learning library Scikit-learn provides OneHotEncoder() method that can be used for one hot encoding. Then, there is also the Pandas method called get_dummies() for one hot encoding. The goal of this short article is to show you the difference between them.
Note: Please refer to the full code given at the end of the article.
What is One Hot Encoding?
If a categorical column has k unique categories then applying one hot encoding technique will create k features.The original column that is used for one-hot encoding must be ignored from the further process.
For example, let’s say, the categorical column Airline has 3 categories: United Airlines, Delta Air Lines, and American Airlines. The one-hot encoding will create 3 features as shown below.
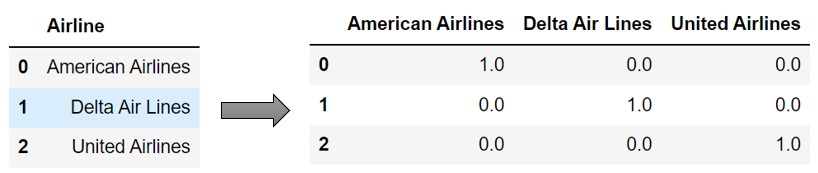
Now, let’s see how one-hot encoding is done using Scikit-learn and Pandas. For the demonstration, we’ll be using the tips dataset from the Seaborn library. Note that we are only using the subset of columns.
import seaborn as sns
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.compose import ColumnTransformer
df = sns.load_dataset('tips')
df = df[['total_bill', 'tip', 'day', 'size']]
Scikit-learn One Hot Encoding
To use one-hot encoding from Scikit-learn, you need to import OneHotEncoder from sklearn.preprocessing.
from sklearn.preprocessing import OneHotEncoder
OneHotEncoder(*, categories='auto', drop=None, sparse=True, dtype=<class>, handle_unknown='error')</class>
- categories — the default value ‘auto’ will identify the unique categories in the column. You can also pass it as a list.
- drop — if set to ‘first’ it will delete the first category and if set to ‘if_binary’ remove the first category if the column has only 2 categories. The default is None.
- sparse — If set to True, it will return the result of one-hot encoding as a sparse matrix otherwise return a NumPy array. The default is True.
- dtype — the datatype of the result.
- handle_unknown — this is an important parameter. If ‘raise’, when an unknown categorical feature is present it will raise the error. If ‘ignore’, a new feature will be created with all values of zero.
Example —
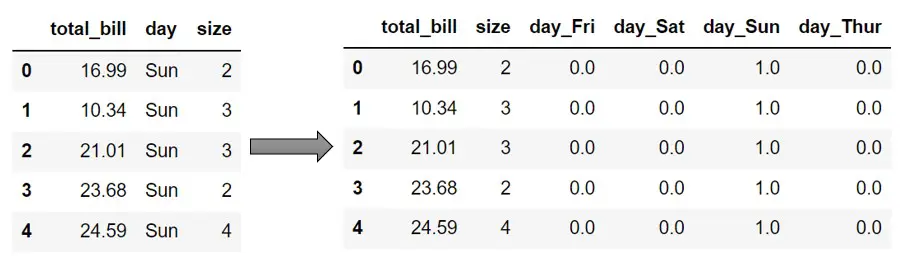
First, you need to create the OneHotEncoder object. Then you need to call the fit() method on train data and then transform() method on both train and test to get one hot encoded feature.
X = df.drop('tip', axis=1)
y = df['tip']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
ohe = OneHotEncoder(sparse=False)
ohe.fit(X_train[['day']])
def get_ohe(df):
temp_df = pd.DataFrame(data=ohe.transform(df[['day']]), columns=ohe.get_feature_names_out())
df.drop(columns=['day'], axis=1, inplace=True)
df = pd.concat([df.reset_index(drop=True), temp_df], axis=1)
return df
X_train = get_ohe(X_train)
X_test = get_ohe(X_test)
Pandas get_dummies
The get_dummies method of Pandas is another way to create one-hot encoded features.
import pandas as pd
pd.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)
- data — the dataframe on which you want to apply one-hot encoding.
- prefix — the prefix you want to append to each category column. For example, if ‘day’ is the column name, then you may want to append day_ to each one-hot encoded feature and then pass
prefix = ['day_']. If more than one column is one hot encoded then pass the list of values. The default is None. - prefix_sep — it is a prefix separator. You can use ‘-’ or ‘_’ or any valid separator. The default is ‘_’.
- dummy_na — if set to True, a new column named NaN will be added to indicate the missing values. Default is false.
- columns — list of columns on which one-hot encoding to be applied.
- sparse — If set to True result will be a sparse matrix otherwise NumPy array. The default is False.
- drop_first — if set to True the result will have k-1 categories out of k categories. The default is False.
Example —
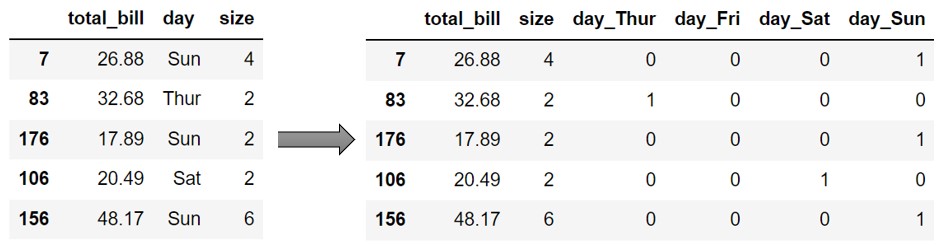
Pandas get_dummies doesn’t have fit and transform methods. At the least, you need to pass the dataframe name and the name of columns on which one hot encoded to be applied, you get the results back. Refer to the sample example below.
X = df.drop('tip', axis=1)
y = df['tip']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
X_train = pd.get_dummies(X_train, columns=['day'])
X_test = pd.get_dummies(X_test, columns=['day'])
You have now understood how to use Sklearn OneHotEncoder and Pandas get_dummies method to encode categorical features. In the next section, let’s see the difference between them.
Differences between OneHotEncoder and get_dummies
Both OneHotEncoder and get_dummies give the same results. But there are some important differences between them.
(1) The get_dummies can’t handle the unknown category during the transformation natively. You have to apply some techniques to handle it. But it is not efficient. On the other hand, OneHotEncoder will natively handle unknown categories. All you need to do is set the parameter handle_unknown='ignore' to OneHotEncoder.
For example, in the tips dataset you have seen above, the day column contains four unique values — Thur, Fri, Sat, and Sun. If the test dataset contains a new category, say Mon or Tue, then the get dummies will create a new column day_Mon or day_Tue which will be inconsistent with train data and will eventually fail during the model building process.
get_dummies example — The get_dummies method doesn’t store the information about train data categories. Hence it may result in inconsistencies with train and test data features. In the below example, X_test_new contains only 2 categories “Sun” and “Mon”. As expected get_dummies will create only 2 columns “day_Mon” and “day_Sun” which is inconsitent with train data columns. The get_dummies doesn’t have the knowledge about train data columns.
X_test_new = pd.DataFrame( {'total_bill': [25, 45], 'day': ['Sun', 'Mon'], 'size': [2, 4]} )
pd.get_dummies(X_test_new, columns=['day']).head()

Though get_dummies can’t handle unknown categories natively, you could get around this inconsistency by applying the below technique. You will have to save the columns of the train set and load it during prediction on test set. Then you need to apply reindex and after filling the missing values will get you the same features as the train set. Refer below.
X_test_new = pd.get_dummies(X_test_new, columns=['day'])
X_test_new.reindex(columns=cols).fillna(0)
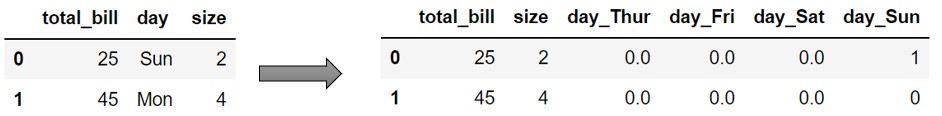
OneHotEncoder example — OneHotEncoder object stores the information about categories from the training dataset. So, whenever it encounters any unknown categories during transformation on test set, it will ignore them and the number of features will remain the same as the training data.
In the below example, even though there is an unknown category ‘Mon’ in the X_test_new, OneHotEncoder ignores the new feature and make sure that the final features will be the same as the training data.
X_test_new = pd.DataFrame( {'total_bill': [25, 45], 'day': ['Sun', 'Mon'], 'size': [2, 4]} )
get_ohe(X_test_new)

(2) If you want to put your machine learning model into production, Scikit-learn Pipeline will be very useful. But, get_dummies is not compatible with the Scikit-learn pipeline. It requires you to create your own transformer. On the other hand, OneHotEncoder is compatible with the Scikit-learn pipeline. Wondering how OneHotEncoder comes in handy with the pipeline? Refer to the code samples below —
OneHotEncoder
As you can see from the below example, OneHotEncoder is compatible with Pipeline and is very easy to use.
X = df.drop('tip', axis=1)
y = df['tip']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
numeric_preprocessor = Pipeline(steps=[
("scaler", MinMaxScaler())
])
categorical_preprocessor = Pipeline(steps=[
("onehot", OneHotEncoder(handle_unknown="ignore"))
])
preprocessor = ColumnTransformer([
("categorical", categorical_preprocessor, ["day"]),
("numerical", numeric_preprocessor, ["total_bill", "size"])
])
pipe = Pipeline(steps=[
("preprocessor", preprocessor),
("classifier", LinearRegression())
])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)
# Output: 0.5706168878130049
X_test_new = pd.DataFrame( {'total_bill': [25, 45], 'day': ['Sun', 'Mon'], 'size': [2, 4]} )
pipe.predict(X_test_new)
# Output: array([3.27325822, 5.436413 ])
get_dummies
In order to use get_dummies in the Sklearn pipeline, you have to write a custom transformer, PreprocessorTransformer in the below example. Then you also need to pass the list of columns you should consider building the model.
X = df.drop('tip', axis=1)
y = df['tip']
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0)
cols = ["total_bill", "size", "day_Fri", "day_Sat", "day_Sun", "day_Thur"]
from sklearn.base import BaseEstimator, TransformerMixin
class PreprocessorTransformer(BaseEstimator, TransformerMixin):
def __init__(self, cols):
self.cols = cols
def fit(self, X, y = None):
return self
def transform(self, X, y = None):
X = pd.get_dummies(X, columns=['day'])
X = X.reindex(columns=self.cols).fillna(0)
return X[self.cols]
preprocessor = Pipeline(steps=[
("preprocessor", PreprocessorTransformer(cols))
])
pipe = Pipeline(steps=[
("preprocessor", preprocessor),
("classifier", LinearRegression())
])
pipe.fit(X_train, y_train)
pipe.score(X_test, y_test)
# Output: 0.5706168878130053
X_test_new = pd.DataFrame( {'total_bill': [25, 45], 'day': ['Sun', 'Mon'], 'size': [2, 4]} )
pipe.predict(X_test_new)
# Output: array([3.27325822, 5.436413 ])
Code
Summary
The one-hot encoding is one of the categorical data encoding techniques. There are two popular and commonly used methods — Scikit-learn OneHotEncoder and Pandas get_dummies method. Both achieve the same result. If you are building the machine learning models then go for OneHotEncoder and for data analysis tasks you can consider either OneHotEncoder or get_dummies.
